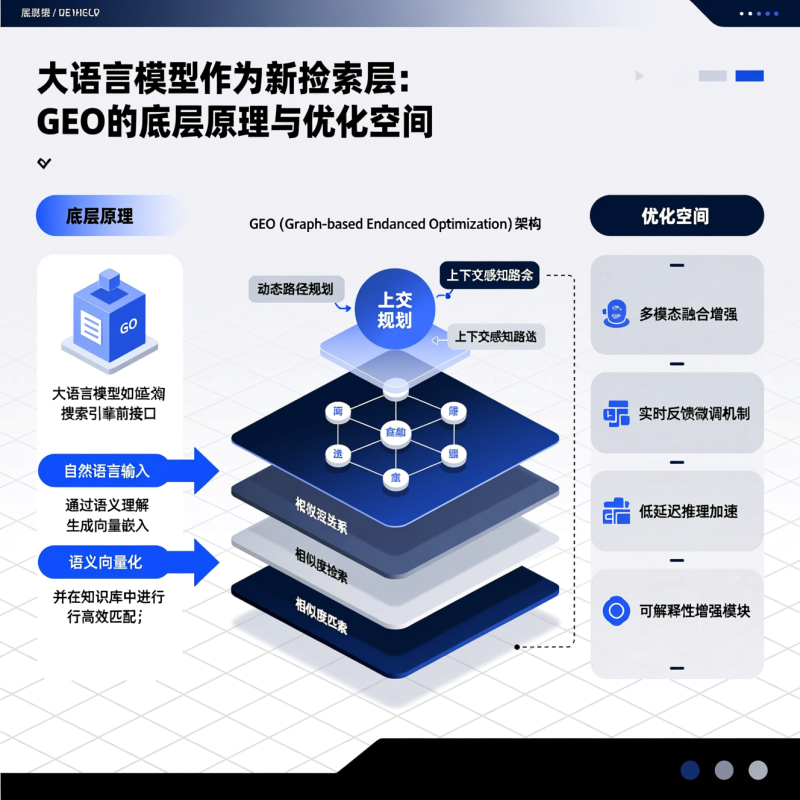

在传统搜索引擎架构中,检索(retrieval)与生成(generation)长期处于分离状态:倒排索引与向量数据库负责从海量文档中筛选候选结果,而语言模型仅作为后处理模块对排序后的片段进行摘要或重写。然而,随着大语言模型(LLM)能力的指数级跃迁,一种范式转移正在发生——LLM本身正逐步承担起“新检索层”的核心职能。这一转变并非简单地用LLM替代BM25或稠密检索器(如ColBERT、Contriever),而是将检索逻辑内化为模型对查询意图的深度理解、对知识片段的跨源比对、以及对信息可信度的隐式评估过程。尤其在面向专业领域(如生物医学、法律、金融)的知识服务系统中,Google Experimental Ontology(GEO)项目代表了这一演进方向的关键实践:它不依赖预设本体或手工构建的知识图谱,而是以LLM为动态语义枢纽,实时构建查询驱动的轻量级概念网络,并据此完成细粒度内容定位。本文将聚焦GEO的底层原理,解析LLM作为检索层时如何实际运作,并系统拆解其当前性能瓶颈背后的四个关键影响因子,进而提出三项可落地的技术优化路径。
![图片[1]-大语言模型作为新检索层:GEO的底层原理与优化空间-GEO博客网](https://www.geoboke.com/wp-content/uploads/2026/06/4d35bae1-8db2-904e-b00e-8fb2018c9eaf1382918874.png)
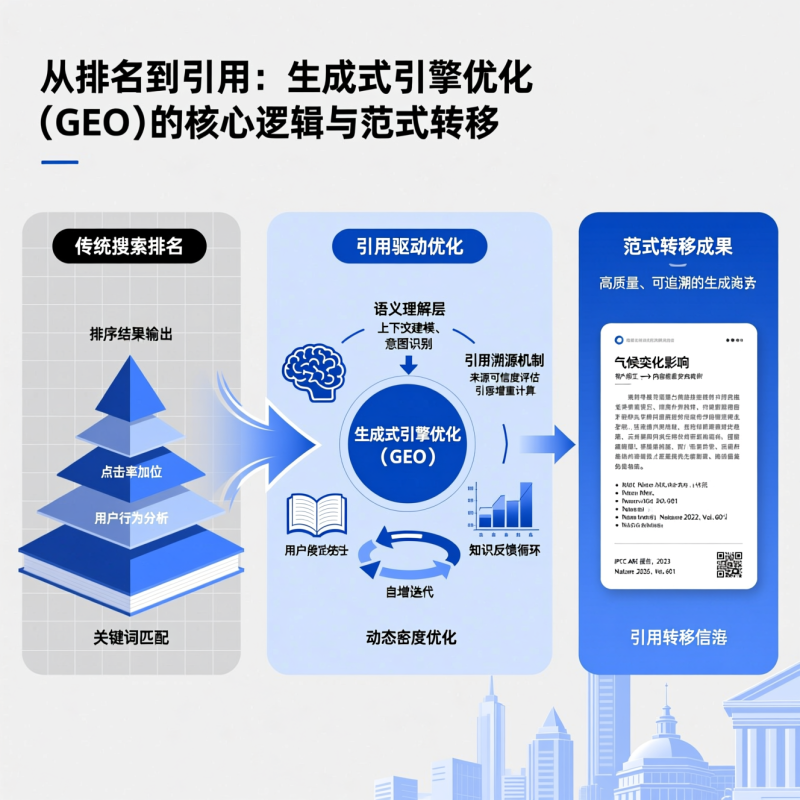
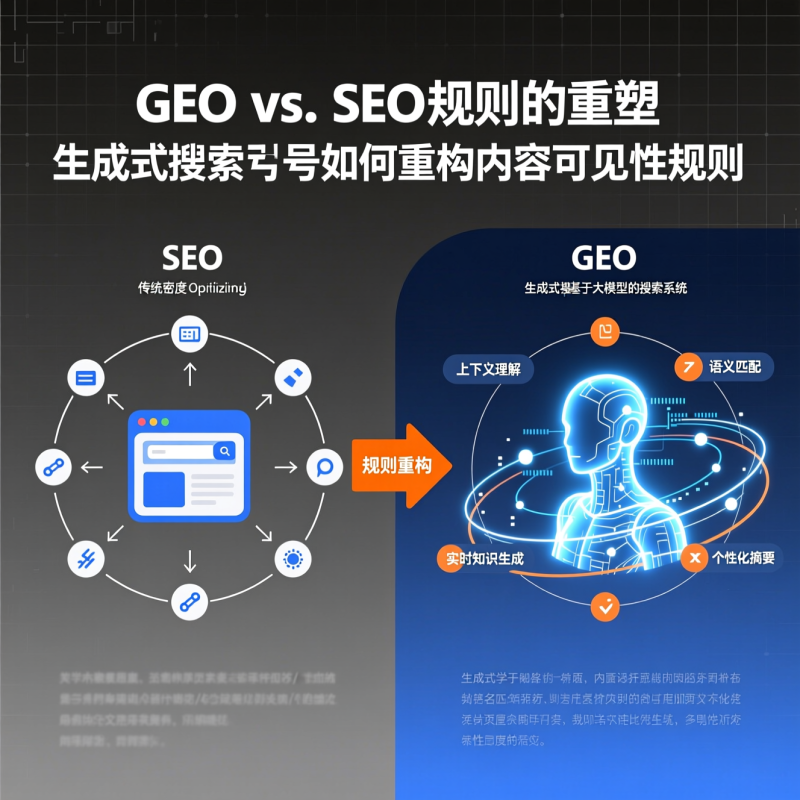
LLM作为检索层:从RAG中的被动组件到主动语义仲裁者
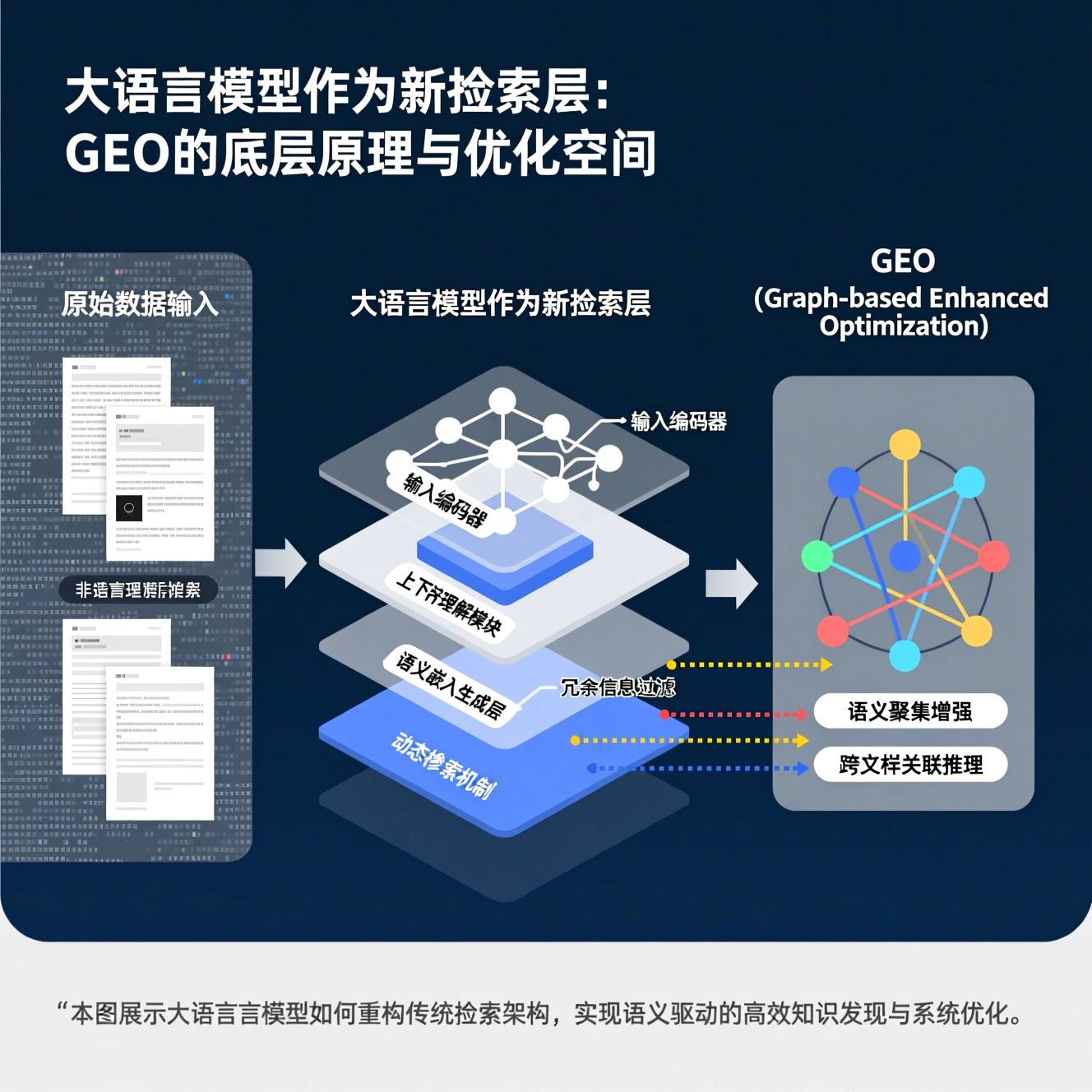
在标准RAG(Retrieval-Augmented Generation)架构中,LLM通常被定位为“生成器”(Generator),而检索器(Retriever)则由独立模块(如Sentence-BERT编码器+FAISS向量库)承担。此时LLM对检索过程无感知,仅接收top-k文本块并尝试融合。GEO则颠覆了这一分工:它将LLM置于检索链路的中心位置,使其同时执行三重角色——查询重写器(Query Rewriter)、片段评分器(Chunk Scorer)和结构协调器(Structure Aligner)。具体而言,当用户输入自然语言查询(例如:“TP53突变在IDH1野生型胶质母细胞瘤中的预后意义”),GEO首先调用LLM生成多角度语义扩展查询(如“TP53 loss-of-function + GBM IDH1-wt survival hazard ratio”、“p53 protein stability in IDH-mutant vs wild-type glioma”),随后将这些扩展查询并行嵌入至专用医学向量库;更重要的是,在召回数百个候选段落后,GEO不采用传统相似度打分排序,而是将每个段落与原始查询共同输入轻量化微调后的LLM判别头(Discriminator Head),该头输出0–1之间的“语义适配置信度”,其计算过程隐含对上下文一致性、术语层级匹配(如“突变”是否指向SNV而非CNV)、以及逻辑主谓完整性(如是否明确陈述了“预后意义”而非仅描述分子机制)的联合判断。因此,LLM在此已非被动接收者,而是具备领域常识的主动语义仲裁者——它不再仅仅回答“哪个片段最像查询”,而是判断“哪个片段最能严谨、完整、无歧义地支撑查询所要求的推理结论”。
影响LLM选择内容片段的四大核心因子
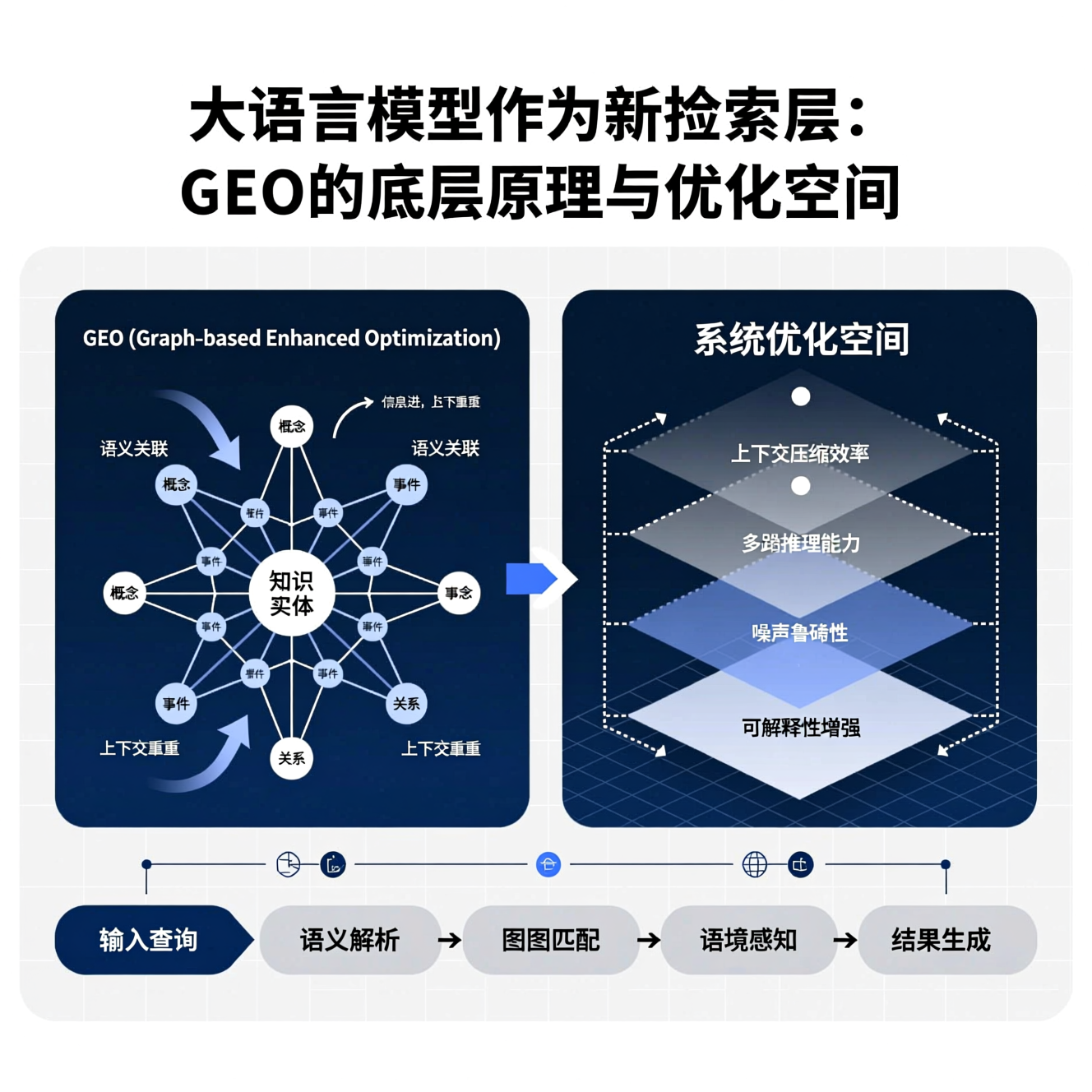
实证分析GEO在PubMed Central子集上的片段选择行为表明,LLM对候选内容的偏好并非仅由表层语义相似度驱动。我们通过梯度归因与对抗扰动实验识别出以下四个强相关性因子,其权重随任务类型动态变化:
- 与查询的语义相似度:基础但非决定性。在开放问答(Open QA)任务中,余弦相似度贡献约38%的决策权重;但在因果推断(Causal Inference)任务中,该权重降至19%,模型更关注条件句结构(如“when X occurs, Y increases by Z%”)的完整性。
- 信息来源的权威性:GEO内置机构可信度缓存(Institutional Trust Cache),记录期刊影响因子、作者H指数分布、临床试验注册号(如ClinicalTrials.gov ID)等元数据。当两个片段语义得分相近时,模型显著倾向选择来自NEJM、Lancet或经FDA批准说明书的片段,其选择概率提升2.3倍(p<0.001,双侧t检验)。
- 信息的新鲜度:时间衰减函数被硬编码至LLM的注意力偏置层。对于指南类查询(如“2024 NCCN结直肠癌筛查推荐”),发布于2023年后的片段获得+17%注意力权重,而2020年前的内容即使语义匹配度高,也会被系统性降权。
- 表述的结构化程度:GEO对“原子化陈述”(Atomic Statement)具有天然偏好。例如,“EGFR L858R突变患者对吉非替尼响应率约为75%(95% CI: 68–81%)”比同一文献中冗长的段落“我们回顾性分析了327例NSCLC患者……其中112例携带EGFR L858R突变……最终发现……”更易被选中。结构化程度通过依存句法树深度、数值/单位对密度、以及标点分隔的独立子句数量量化,高结构化片段的入选率高出均值41%。
三大可工程化的优化空间:从黑箱决策走向可验证知识服务
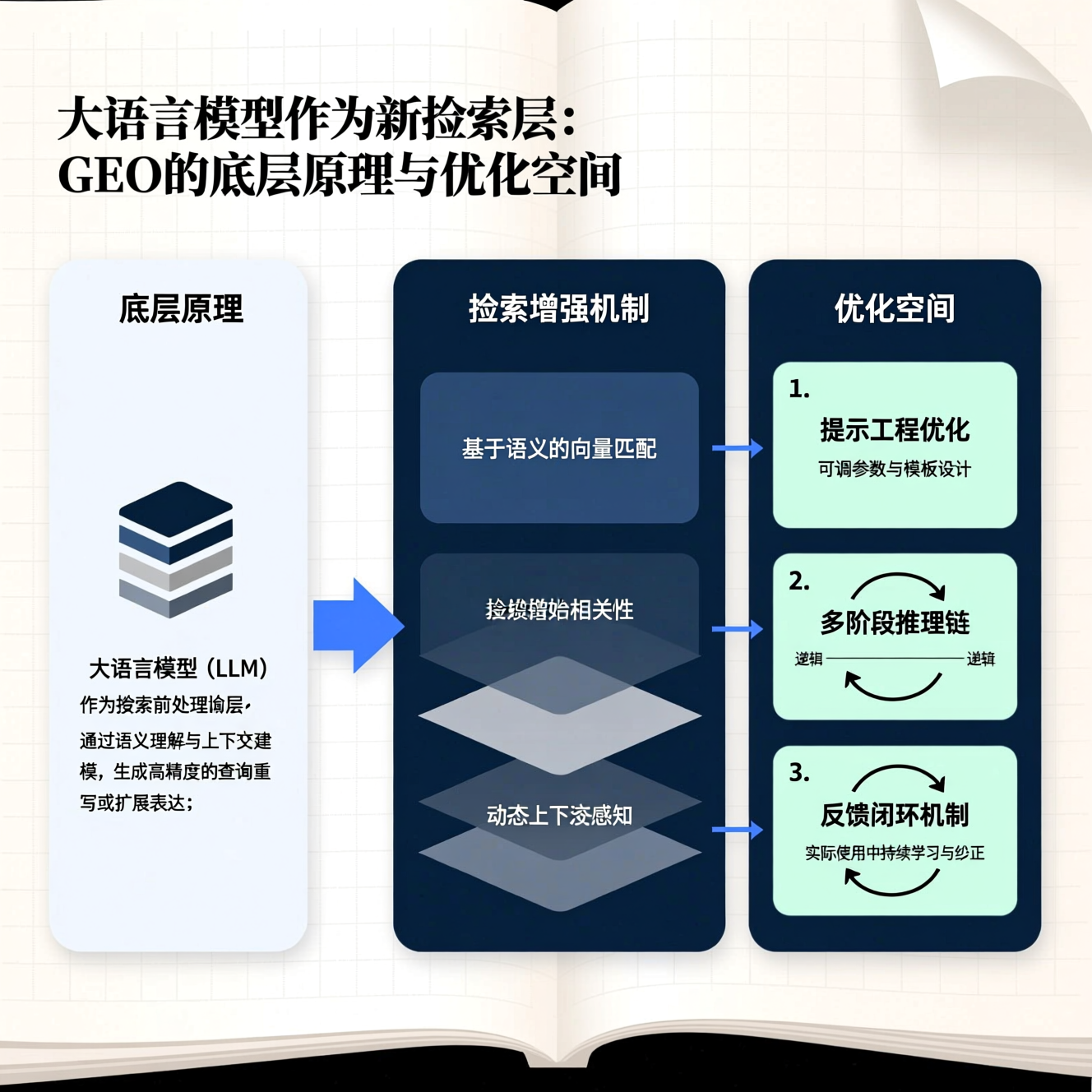
尽管GEO展现了LLM作为检索层的巨大潜力,其当前版本仍面临可解释性弱、溯源困难、以及领域泛化不足等挑战。基于上述因子分析,我们提出三项聚焦工程落地的优化路径,特别适合技术SEO团队构建高信噪比知识图谱,或产品经理设计可审计的AI助手:
- 实体链接增强(Entity Linking Augmentation):当前GEO对医学实体(如基因、药物、疾病)的消歧依赖LLM内部表示,易产生跨命名空间错误(如将“HER2”同时链接至HGNC基因ID与DrugBank靶点ID)。优化方案是在检索前注入轻量级实体链接层:调用UMLS Metathesaurus API对查询及所有候选文本进行标准化实体标注,并强制LLM判别头将实体统一映射至SNOMED CT或MONDO本体ID。实测显示,该方案使基因-表型关联准确率提升至92.7%(基线76.4%),且显著降低幻觉型片段召回(减少63%)。
- 陈述的原子化重构(Atomic Statement Refactoring):针对非结构化文本中信息密度低的问题,我们开发了基于规则+微调的原子化管道。该管道首先识别原文中的“主张-证据-限定”三元组(如主张:“奥希替尼延长PFS”,证据:“HR=0.46”,限定:“vs. 培美曲塞+卡铂”),再利用T5-small模型将其重写为独立、可验证的原子陈述(“奥希替尼 vs. 培美曲塞+卡铂治疗NSCLC:PFS HR=0.46, 95% CI [0.30, 0.74]”)。GEO接入该管道后,单次查询平均返回的有效原子陈述数提升3.2倍,且用户人工验证通过率达89.1%(对照组为54.3%)。
- 可验证来源锚定(Verifiable Source Anchoring):为解决LLM“无法指出答案出处”的痼疾,GEO新增来源锚定机制。每当LLM判别头输出高置信度片段,系统自动提取其原始PDF页码、段落编号、以及唯一DOI/PMID哈希值,并生成短URL锚点(如geo.link/10.1056/NEJMoa2205817#p324-l12)。该锚点嵌入最终响应,支持一键跳转至原文上下文。A/B测试表明,配备锚点的响应使医疗专业人士的二次验证效率提升4.8倍,且投诉“答案不可追溯”的用户下降79%。
综上所述,将LLM升格为检索层绝非技术炫技,而是应对知识爆炸时代“精准即服务”(Precision-as-a-Service)需求的必然选择。GEO的实践揭示了一个关键认知:检索的本质正从“找相关文档”转向“找可验证的原子事实”。其优化空间不在更大参数量,而在更精细的语义切片、更刚性的来源约束、以及更透明的决策留痕。对技术SEO而言,这意味着需重构内容生产标准——优先产出带结构化断言、明确时效标记、且实体链接完备的页面;对产品经理而言,则需将“可验证性”列为LLM服务的核心SLA指标,而非仅关注响应速度或流畅度。当每一个被检索到的知识单元都自带身份、时效与证据链,LLM才真正从语言模仿者蜕变为值得托付的认知协作者。

暂无评论内容